什么是cookie?
是存储在客户端的一组键值对
web中cookie的典型应用:登陆请求

cookie和爬虫之间的关联:
sometime,对一张页面进行请求的时候,如何请求的过程中不携带cookie的话,那么我们是无法请求到正确的页面数据。因此cookie是爬虫中一个非常典型且常见的反爬机制
还是照旧,我们以实际例子看下:
需求:爬取某球网中的网页数据。
正常思路分析:
- 判定爬取的咨询数据是否为动态加载数据
- 此网页下滑可以更新数据,不用分析都知道肯定是这个动态加载数据的。
- 相关的更多咨询数据是动态加载的,滚轮滑动到底部的时候会动态加载更多的数据
- 那我们就定位到ajax请求的数据表,提取出请求的url,响应的数据为json形式的数据
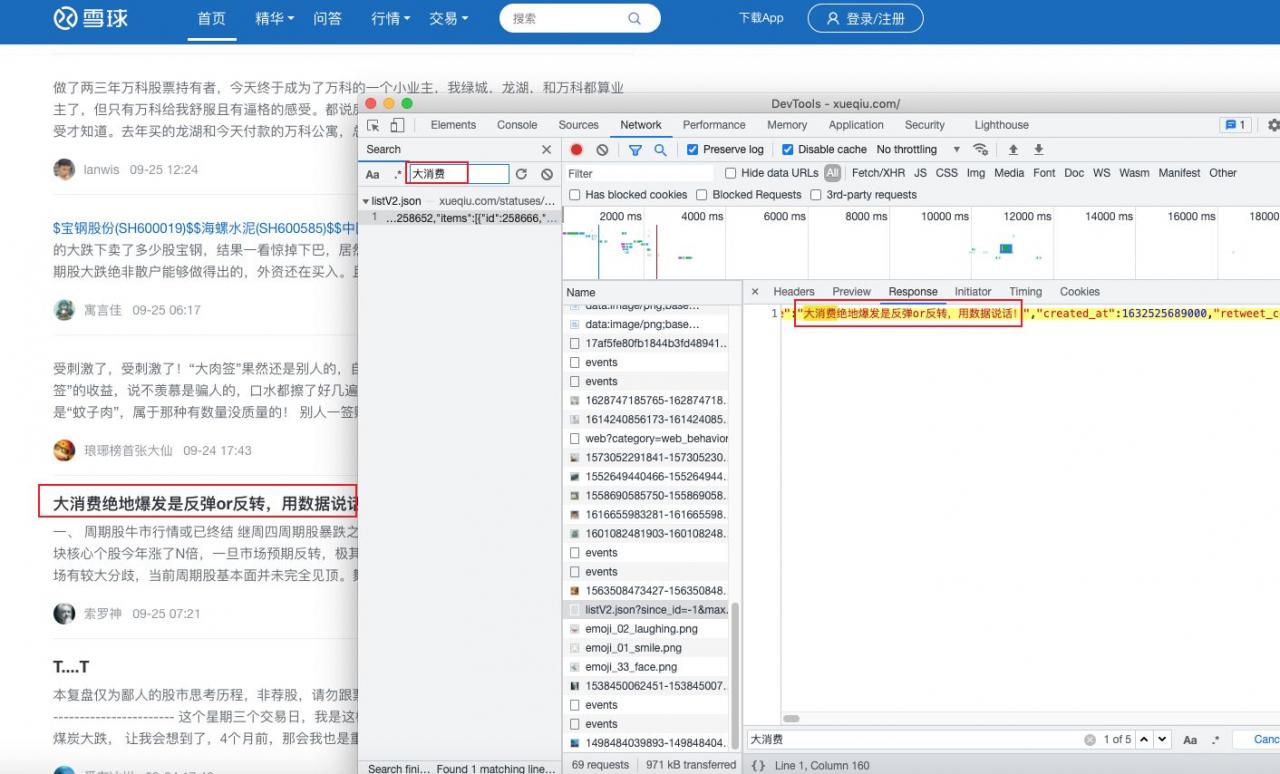
代码实现:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
url = 'https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=258231&size=15'
page_text = requests.get(url=url, headers=headers).json()
print(page_text)
爬取结果:

额,直接就打印个错误!那看来用我们以往的正常方式爬取是不行的
cookie处理
上面的问题:我们没有请求到我们想要的数据
原因:我们没有严格意义上模拟浏览器发请求
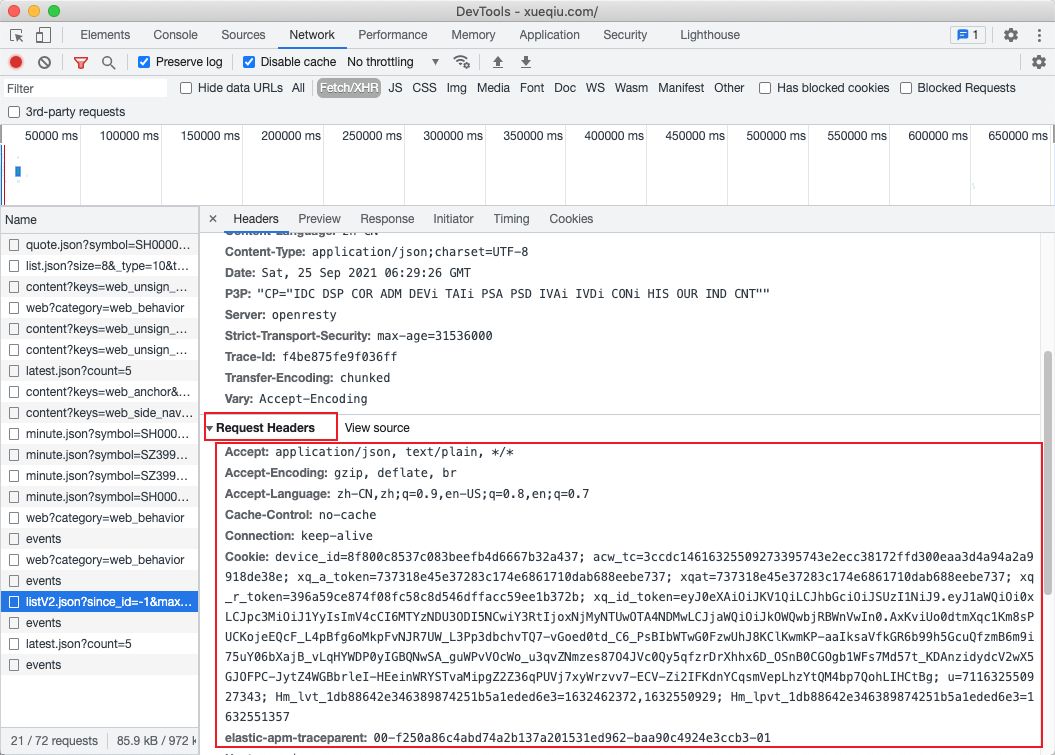
我们发现,请求头跟之前学习的网站不一样。这个请求头里有很多内容,尤其是cookie比较多,那么可以确定,这个地址是需要携带cookie才可以访问的。
处理:可以将浏览器发请求携带的请求头,全部粘贴在headers字典中,将headers坐拥到requests的请求操作中即可
处理之前,先介绍下 cookies的处理的方式:
- 方式1:手动处理:
1. 将抓包工具中的cookie粘贴在headers中
2. 弊端:cookie如何获得有效市场则该方式失效
这种方式虽然简单有效,但众所周知,cookie是有有效期的。比如:我们登陆了一个网站,长时间不去再次登陆的话,浏览器就不会自动登陆了。
这种方式适合短暂爬取数据比较方便。
- 方式2:自动处理
1. 基于session对象实现自动处理
如何获取一个Session对象:requeste.Session()返回一个session对象
2. session对象的作用:
该对象可以向requests一样调用get和post发起指定的请求。
只不过如果在使用session发请求的过程中如果产生了cookie,则cookie会被自动存储到该session对象中,那么就意味着下次在使用session对象发起请求,则该次请求就是携带cookie进行的请求发送。
在爬虫中使用session的时候,session对象至少会被使用几次?
两次,第一次使用session是为了将cooike捕获存储到session对象中。 下次的时候就是携带cookie进行的请求发送
我们来重写下上面的代码:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
# 创建session对象
session = requests.Session()
# 第一次使用session捕获且存储cookies,猜测对某球网的首页发起的请求可能会产生cookie
main_url = 'https://xueqiu.com/'
session.get(url=main_url, headers=headers) # 捕获且存储cookie
url = 'https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=258231&size=15'
page_text = session.get(url=url, headers=headers).json() # 携带cookie发起的请求
print(page_text)
果然,我们爬取到了数据!
cookie是最常见的反爬机制之一,我们一定要熟悉分析和写作。
关注 Python涛哥,学习更多Python知识!
以上内容来源于网络,由“WiFi之家网”整理收藏!
原创文章,作者:电脑教程,如若转载,请注明出处:https://www.224m.com/225895.html